Collaborative Filtering with R
https://drsurdis.com/cryotherapy/ ![]() Posted by Salem on April 26, 2014
Posted by Salem on April 26, 2014
go to site We already looked at Market Basket Analysis with R. http___www.bigleaguekickball.com_category_press_ soma overnight delivery only Collaborative filtering is another technique that can be used for recommendation.
https://destinylootcave.com/malfeasance/ The underlying concept behind this technique is as follows:
- Assume Person A likes Oranges, and Person B likes Oranges.
- Assume Person A likes Apples.
- Person B is likely to have similar opinions on Apples as A than some other random person.
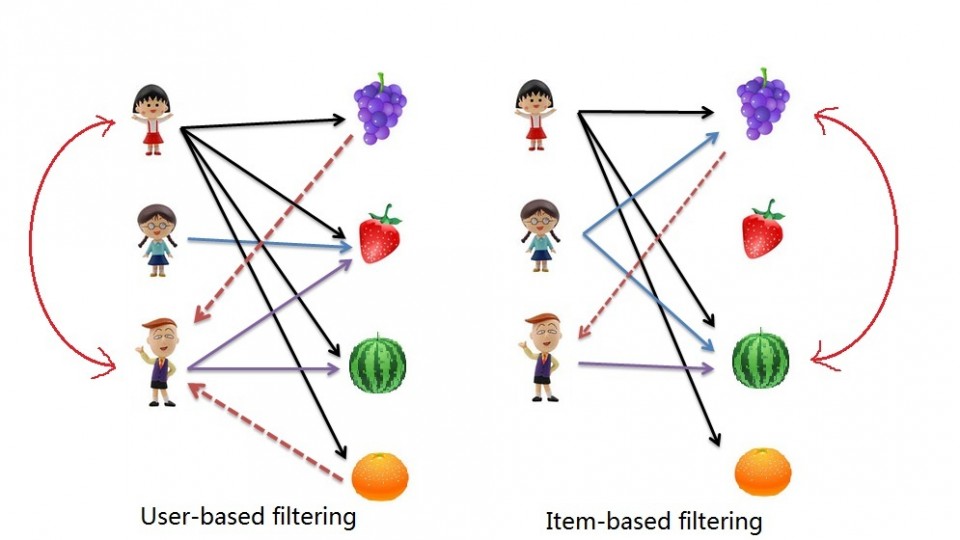
Order Tramadol Overnight The implications of collaborative filtering are obvious: you can predict and recommend items to users based on preference similarities. There are two types of collaborative filtering: user-based and item-based.
https://detoxofcolorado.com/referring-professionals/ http___www.bigleaguekickball.com_about_ Soma online ordering next day VISA Mastercard accepted Item Based Collaborative Filtering takes the similarities between items’ consumption history.
source url User Based Collaborative Filtering considers similarities between user consumption history.
Tramadol Online Purchase We will look at both types of collaborative filtering using a publicly available dataset from LastFM.
Case: Last.FM Music
Ambien Online Ordering The data set contains information about users, their gender, their age, and which artists they have listened to on Last.FM. We will not use the entire dataset. For simplicity’s sake we only use songs in Germany and we will transform the data to a item frequency matrix. This means each row will represent a user, and each column represents and artist. For this we use R’s “reshape” package. This is largely administrative, so we will start with the transformed dataset.
Zolpidem Online Order Download the LastFM Germany frequency matrix and put it in your working directory. Load up R and read the data file.
https://brunobianco.com.br/parceiros/ # Read data from Last.FM frequency matrix data.germany <- read.csv(file="lastfm-matrix-germany.csv") |
Tramadol Online Purchase # Read data from Last.FM frequency matrix data.germany <- read.csv(file="lastfm-matrix-germany.csv")
Order Soma 350Mg Online Lets look at a sample of our data. The output looks something like this:
Buy Clonazepam Without Prescription head(data.germany[,c(1,3:8)]) user abba ac.dc adam.green aerosmith afi air 1 1 0 0 0 0 0 0 2 33 0 0 1 0 0 0 3 42 0 0 0 0 0 0 4 51 0 0 0 0 0 0 5 62 0 0 0 0 0 0 6 75 0 0 0 0 0 0 |
here head(data.germany[,c(1,3:8)]) user abba ac.dc adam.green aerosmith afi air 1 1 0 0 0 0 0 0 2 33 0 0 1 0 0 0 3 42 0 0 0 0 0 0 4 51 0 0 0 0 0 0 5 62 0 0 0 0 0 0 6 75 0 0 0 0 0 0
Order Soma Online We’re good to go!
Item Based Collaborative Filtering
https://destinylootcave.com/planet-mats/ In item based collaborative filtering we do not really care about the users. So the first thing we should do is drop the user column from our data. This is really easy since it is the first column, but if it was not the first column we would still be able to drop it with the following code:
# Drop any column named "user" data.germany.ibs <- (data.germany[,!(names(data.germany) %in% c("user"))]) |
We then want to calculate the similarity of each song with the rest of the songs. This means that we want to compare each column in our “data.germany.ibs” data set with every other column in the data set. Specifically, we will be comparing what is known as the “Cosine Similarity”.
The cosine similarity, in essence takes the sum product of the first and second column, and divide that by the product of the square root of the sum of squares of each column. (that was a mouth-full!)
The important thing to know is the resulting number represents how “similar” the first column is with the second column. We will use the following helper function to product the Cosine Similarity:
# Create a helper function to calculate the cosine between two vectors getCosine <- function(x,y) { this.cosine <- sum(x*y) / (sqrt(sum(x*x)) * sqrt(sum(y*y))) return(this.cosine) } |
We are now ready to start comparing each of our songs (items). We first need a placeholder to store the results of our cosine similarities. This placeholder will have the songs in both columns and rows:
# Create a placeholder dataframe listing item vs. item data.germany.ibs.similarity <- matrix(NA, nrow=ncol(data.germany.ibs),ncol=ncol(data.germany.ibs),dimnames=list(colnames(data.germany.ibs),colnames(data.germany.ibs))) |
The first 6 items of the empty placeholder will look like this:
a.perfect.circle abba ac.dc adam.green aerosmith afi a.perfect.circle NA NA NA NA NA NA abba NA NA NA NA NA NA ac.dc NA NA NA NA NA NA adam.green NA NA NA NA NA NA aerosmith NA NA NA NA NA NA afi NA NA NA NA NA NA |
Perfect, all that’s left is to loop column by column and calculate the cosine similarities with our helper function, and then put the results into the placeholder data table. That sounds like a pretty straight-forward nested for-loop:
# Lets fill in those empty spaces with cosine similarities # Loop through the columns for(i in 1:ncol(data.germany.ibs)) { # Loop through the columns for each column for(j in 1:ncol(data.germany.ibs)) { # Fill in placeholder with cosine similarities data.germany.ibs.similarity[i,j] <- getCosine(as.matrix(data.germany.ibs[i]),as.matrix(data.germany.ibs[j])) } } # Back to dataframe data.germany.ibs.similarity <- as.data.frame(data.germany.ibs.similarity) |
Note: For loops in R are infernally slow. We use as.matrix() to transform the columns into matrices since matrix operations run a lot faster. We transform the similarity matrix into a data.frame for later processes that we will use.
We have our similarity matrix. Now the question is … https://bodyandskinclinic.com/ecxcelis/ so what?
We are now in a position to make recommendations! We look at the top 10 neighbours of each song – those would be the recommendations we make to people listening to those songs.
We start off by creating a placeholder:
# Get the top 10 neighbours for each data.germany.neighbours <- matrix(NA, nrow=ncol(data.germany.ibs.similarity),ncol=11,dimnames=list(colnames(data.germany.ibs.similarity))) |
Our empty placeholder should look like this:
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] a.perfect.circle NA NA NA NA NA NA NA NA NA NA NA abba NA NA NA NA NA NA NA NA NA NA NA ac.dc NA NA NA NA NA NA NA NA NA NA NA adam.green NA NA NA NA NA NA NA NA NA NA NA aerosmith NA NA NA NA NA NA NA NA NA NA NA afi NA NA NA NA NA NA NA NA NA NA NA |
Then we need to find the neighbours. This is another loop but runs much faster.
for(i in 1:ncol(data.germany.ibs)) { data.germany.neighbours[i,] <- (t(head(n=11,rownames(data.germany.ibs.similarity[order(data.germany.ibs.similarity[,i],decreasing=TRUE),][i])))) } |
It’s a little bit more complicated so lets break it down into steps:
- We loop through all our artists
- We sort our similarity matrix for the artist so that we have the most similar first.
- We take the top 11 (first will always be the same artist) and put them into our placeholder
- Note we use t() to rotate the similarity matrix since the neighbour one is shaped differently
The filled in placeholder should look like this:
[,1] [,2] [,3] a.perfect.circle "a.perfect.circle" "tool" "dredg" abba "abba" "madonna" "robbie.williams" ac.dc "ac.dc" "red.hot.chilli.peppers" "metallica" adam.green "adam.green" "the.libertines" "the.strokes" aerosmith "aerosmith" "u2" "led.zeppelin" afi "afi" "funeral.for.a.friend" "rise.against" |
This means for those listening to Abba we would recommend Madonna and Robbie Williams.
Likewise for people listening to ACDC we would recommend the Red Hot Chilli Peppers and Metallica.
User Based Recommendations
We will need our similarity matrix for User Based recommendations.
The process behind creating a score matrix for the User Based recommendations is pretty straight forward:
- Choose an item and check if a user consumed that item
- Get the similarities of that item’s top X neighbours
- Get the consumption record of the user of the top X neighbours
- Calculate the score with a formula: sumproduct(purchaseHistory, similarities)/sum(similarities)
We can start by creating a helper function to calculate the score mentioned in the last step.
# Lets make a helper function to calculate the scores getScore <- function(history, similarities) { x <- sum(history*similarities)/sum(similarities) x } |
We will also need a holder matrix. We will use the original data set now (data.germany):
# A placeholder matrix holder <- matrix(NA, nrow=nrow(data.germany),ncol=ncol(data.germany)-1,dimnames=list((data.germany$user),colnames(data.germany[-1]))) |
The rest is one big ugly nested loop. First the loop, then we will break it down step by step:
# Loop through the users (rows) for(i in 1:nrow(holder)) { # Loops through the products (columns) for(j in 1:ncol(holder)) { # Get the user's name and th product's name # We do this not to conform with vectors sorted differently user <- rownames(holder)[i] product <- colnames(holder)[j] # We do not want to recommend products you have already consumed # If you have already consumed it, we store an empty string if(as.integer(data.germany[data.germany$user==user,product]) == 1) { holder[i,j]<-"" } else { # We first have to get a product's top 10 neighbours sorted by similarity topN<-((head(n=11,(data.germany.ibs.similarity[order(data.germany.ibs.similarity[,product],decreasing=TRUE),][product])))) topN.names <- as.character(rownames(topN)) topN.similarities <- as.numeric(topN[,1]) # Drop the first one because it will always be the same song topN.similarities<-topN.similarities[-1] topN.names<-topN.names[-1] # We then get the user's purchase history for those 10 items topN.purchases<- data.germany[,c("user",topN.names)] topN.userPurchases<-topN.purchases[topN.purchases$user==user,] topN.userPurchases <- as.numeric(topN.userPurchases[!(names(topN.userPurchases) %in% c("user"))]) # We then calculate the score for that product and that user holder[i,j]<-getScore(similarities=topN.similarities,history=topN.userPurchases) } # close else statement } # end product for loop } # end user for loop data.germany.user.scores <- holder |
The loop starts by taking each user (row) and then jumps into another loop that takes each column (artists).
We then store the user’s name and artist name in variables to use them easily later.
We then use an if statement to filter out artists that a user has already listened to – this is a business case decision.
The next bit gets the item based similarity scores for the artist under consideration.
# We first have to get a product's top 10 neighbours sorted by similarity topN<-((head(n=11,(data.germany.ibs.similarity[order(data.germany.ibs.similarity[,product],decreasing=TRUE),][product])))) topN.names <- as.character(rownames(topN)) topN.similarities <- as.numeric(topN[,1]) # Drop the first one because it will always be the same song topN.similarities<-topN.similarities[-1] topN.names<-topN.names[-1] |
It is important to note the number of artists you pick matters. We pick the top 10.
We store the similarities score and song names.
We also drop the first column because, as we saw, it always represents the same song.
We’re almost there. We just need the user’s purchase history for the top 10 songs.
# We then get the user's purchase history for those 10 items topN.purchases<- data.germany[,c("user",topN.names)] topN.userPurchases<-topN.purchases[topN.purchases$user==user,] topN.userPurchases <- as.numeric(topN.userPurchases[!(names(topN.userPurchases) %in% c("user"))]) |
We use the original data set to get the purchases of our users’ top 10 purchases.
We filter out our current user in the loop and then filter out purchases that match the user.
We are now ready to calculate the score and store it in our holder matrix:
# We then calculate the score for that product and that user holder[i,j]<-getScore(similarities=topN.similarities,history=topN.userPurchases) |
Once we are done we can store the results in a data frame.
The results should look something like this:
X a.perfect.circle abba ac.dc 1 0.0000000 0.00000000 0.20440540 33 0.0823426 0.00000000 0.09591153 42 0.0000000 0.08976655 0.00000000 51 0.0823426 0.08356811 0.00000000 62 0.0000000 0.00000000 0.11430459 75 0.0000000 0.00000000 0.00000000 |
This basically reads that for user 51 we would recommend abba first, then a perfect circle, and we would not recommend ACDC.
This is not very pretty … so lets make it pretty:
We will create another holder matrix and for each user score we will sort the scores and store the artist names in rank order.
# Lets make our recommendations pretty data.germany.user.scores.holder <- matrix(NA, nrow=nrow(data.germany.user.scores),ncol=100,dimnames=list(rownames(data.germany.user.scores))) for(i in 1:nrow(data.germany.user.scores)) { data.germany.user.scores.holder[i,] <- names(head(n=100,(data.germany.user.scores[,order(data.germany.user.scores[i,],decreasing=TRUE)])[i,])) } |
The output of this will look like this:
X V1 V2 V3 1 flogging.molly coldplay aerosmith 33 peter.fox gentleman red.hot.chili.peppers 42 oomph. lacuna.coil rammstein 51 the.subways the.kooks the.hives 62 mando.diao the.fratellis jack.johnson 75 hoobastank papa.roach the.prodigy |
By sorting we see that actually the top 3 for user 51 is the subways, the kooks, and the hives!
References
- Data Mining and Business Analytics with R
- This case is based on Professor Miguel Canela “Designing a music recommendation app”
Entire Code
# Admin stuff here, nothing special options(digits=4) data <- read.csv(file="lastfm-data.csv") data.germany <- read.csv(file="lastfm-matrix-germany.csv") ############################ # Item Based Similarity # ############################ # Drop the user column and make a new data frame data.germany.ibs <- (data.germany[,!(names(data.germany) %in% c("user"))]) # Create a helper function to calculate the cosine between two vectors getCosine <- function(x,y) { this.cosine <- sum(x*y) / (sqrt(sum(x*x)) * sqrt(sum(y*y))) return(this.cosine) } # Create a placeholder dataframe listing item vs. item holder <- matrix(NA, nrow=ncol(data.germany.ibs),ncol=ncol(data.germany.ibs),dimnames=list(colnames(data.germany.ibs),colnames(data.germany.ibs))) data.germany.ibs.similarity <- as.data.frame(holder) # Lets fill in those empty spaces with cosine similarities for(i in 1:ncol(data.germany.ibs)) { for(j in 1:ncol(data.germany.ibs)) { data.germany.ibs.similarity[i,j]= getCosine(data.germany.ibs[i],data.germany.ibs[j]) } } # Output similarity results to a file write.csv(data.germany.ibs.similarity,file="final-germany-similarity.csv") # Get the top 10 neighbours for each data.germany.neighbours <- matrix(NA, nrow=ncol(data.germany.ibs.similarity),ncol=11,dimnames=list(colnames(data.germany.ibs.similarity))) for(i in 1:ncol(data.germany.ibs)) { data.germany.neighbours[i,] <- (t(head(n=11,rownames(data.germany.ibs.similarity[order(data.germany.ibs.similarity[,i],decreasing=TRUE),][i])))) } # Output neighbour results to a file write.csv(file="final-germany-item-neighbours.csv",x=data.germany.neighbours[,-1]) ############################ # User Scores Matrix # ############################ # Process: # Choose a product, see if the user purchased a product # Get the similarities of that product's top 10 neighbours # Get the purchase record of that user of the top 10 neighbours # Do the formula: sumproduct(purchaseHistory, similarities)/sum(similarities) # Lets make a helper function to calculate the scores getScore <- function(history, similarities) { x <- sum(history*similarities)/sum(similarities) x } # A placeholder matrix holder <- matrix(NA, nrow=nrow(data.germany),ncol=ncol(data.germany)-1,dimnames=list((data.germany$user),colnames(data.germany[-1]))) # Loop through the users (rows) for(i in 1:nrow(holder)) { # Loops through the products (columns) for(j in 1:ncol(holder)) { # Get the user's name and th product's name # We do this not to conform with vectors sorted differently user <- rownames(holder)[i] product <- colnames(holder)[j] # We do not want to recommend products you have already consumed # If you have already consumed it, we store an empty string if(as.integer(data.germany[data.germany$user==user,product]) == 1) { holder[i,j]<-"" } else { # We first have to get a product's top 10 neighbours sorted by similarity topN<-((head(n=11,(data.germany.ibs.similarity[order(data.germany.ibs.similarity[,product],decreasing=TRUE),][product])))) topN.names <- as.character(rownames(topN)) topN.similarities <- as.numeric(topN[,1]) # Drop the first one because it will always be the same song topN.similarities<-topN.similarities[-1] topN.names<-topN.names[-1] # We then get the user's purchase history for those 10 items topN.purchases<- data.germany[,c("user",topN.names)] topN.userPurchases<-topN.purchases[topN.purchases$user==user,] topN.userPurchases <- as.numeric(topN.userPurchases[!(names(topN.userPurchases) %in% c("user"))]) # We then calculate the score for that product and that user holder[i,j]<-getScore(similarities=topN.similarities,history=topN.userPurchases) } # close else statement } # end product for loop } # end user for loop # Output the results to a file data.germany.user.scores <- holder write.csv(file="final-user-scores.csv",data.germany.user.scores) # Lets make our recommendations pretty data.germany.user.scores.holder <- matrix(NA, nrow=nrow(data.germany.user.scores),ncol=100,dimnames=list(rownames(data.germany.user.scores))) for(i in 1:nrow(data.germany.user.scores)) { data.germany.user.scores.holder[i,] <- names(head(n=100,(data.germany.user.scores[,order(data.germany.user.scores[i,],decreasing=TRUE)])[i,])) } # Write output to file write.csv(file="final-user-recommendations.csv",data.germany.user.scores.holder) |

![]() Category: Code
Category: Code
![]() Tags: filtering, R, recommender
Tags: filtering, R, recommender


My data has to do with consumers and i want to suggest products to them and I found your code very useful for me.When I tried to use it for 1.000 consumers the code works fine.However, when I selected 200.000 consumers and I tried user-based collaborative filtering, R became extremely slow and the first 12 products recommended were exactly the same for any consumer. Could you suggest me anything for my case?
Thank you in advance!
Pingback: 65 Free Resources to start a career as a Data Scientist for Beginners!! – Data science revolution
Dear Salem I think your code for user user recommendation is not correct as you said we don’t need to recommend an item to a user if he/she already bought, however in your code it seems that you used purchase history for 10 similar items already bought. Particularly I didn’t see a part where you considered similarity of users which is the main component in user user collaborative filtering
How long will the “big ugly nested loop” run? My code has been running for 10 minutes, is that normal?
Hey Salem!
I was inspired by your post to try and use the apply family as opposed to loops. Check out my gist here:
https://gist.github.com/whistlebug23/72dd872c29649b7879222aa2d92d9aaf
I would like to continue to develop this to do more (and fine-tune), but wanted to share a good start. I wanted to give you sufficient credit where it is due!
I found that vectorisation (writing the code in vector/matrix forms) reduces the runtime significantly. I uploaded the code to Github. Hope this helps.
https://gist.github.com/yoshiki146/31d4a46c3d8e906c3cd24f425568d34e
Hi Salem. I got a bit confused with the formula:
sumproduct(purchaseHistory, similarities)/sum(similarities)
Since we are dealing with binary data (purchcase would either be 1 or 0 onlty), would this formula just be equal to 1?
Hi,
would you split the data into train and test when doing IBCF?
please advise