![]() Jan 19
Jan 19

Diving into Data – An SQL Course on Udemy by MBASQL.com

An interactive SQL learning experience
We run a micro-courses business, Afterskills, to help professionals ramp up their skills on specific and technical topics.
One of our products, MBASQL, is designed to help MBA’s, Business Analysts, and other professionals in Marketing, Online Fashion, and E-Commerce ramp up their skills with Data.
Today, we launched that course online through Udemy.com
Course Description
Our course is designed to equip MBAs & professionals with the skills required to extract data from relational databases. Most importantly, students will learn how to use data to bring insight into their decision making process through the lens of commercial problems faced by leading e-commerce businesses.
To assist in your learning, you will gain access to our very own:
- Simulated web store having the same functionality as all e-commerce businesses.
- Rich database of customer & product information that you’ll be able to browse.
- SQL platform to take what you’ve learned & turn that into your very own SQL code.
Start Learning SQL with MBASQL.com
The class can be found here:
https://www.udemy.com/mbasql-diving-into-data/
The first 100 students can get a 50% discount by using the coupon code “MBASQL-FRIEND”
Please leave a review if you do take the course!
Thanks!!
![]() Posted by Salem
Posted by Salem
![]() Aug 8
Aug 8

Recursively rename files to their parent folder’s name

If you own a business and sell online, you will have had to – at some point or another – name a whole bunch of images in a specific way to stay organised. If you sell on behalf of brands, naming your images is even more important.
Problem: Lets say you had your images sorted in a bunch of folders. Each folder had the name of the brand with the brand’s images in the folder. To make it more complicated, a brand could have a sub-brand, and therefore a subfolder with that sub-brand’s images.
This looks like this in practice:
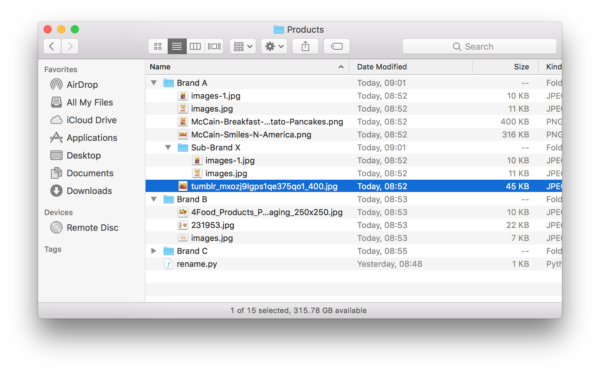
I was surprised at how difficult this was to accomplish. After scouring stack overflow for solutions that do something close, I came up with the solution presented here.
We will be using Python’s os library. First lets create a function that takes 2 parameters:
- The top-most folder that contains all the files and subfolders.
- A number indicating how many folders deep do we want to go
This look like this:
def renameFiles(path, depth=99): |
We will be calling this function recursively (over and over) until we are as deep as we want to go. For every folder deep we go, we want to reduce the depth by one. If we hit 0, then we know to go back up the folder tree. Lets continue building our code:
def renameFiles(path, depth=99): if depth < 0: return |
Now for every file we hit, we want to test for a few things:
- That the path to that file is not a shortcut or symbolic link
- That the path to the file is a real folder and exists
- If the file we look at is a real folder, we go one level deep
To do this we add the following code:
def renameFiles(path, depth=99): # Once we hit depth, return if depth < 0: return # Make sure that a path was supplied and it is not a symbolic link if os.path.isdir(path) and not os.path.islink(path): # We will use a counter to append to the end of the file name ind = 1 # Loop through each file in the start directory and create a fullpath for file in os.listdir(path): fullpath = path + os.path.sep + file # Again we don't want to follow symbolic links if not os.path.islink(fullpath): # If it is a directory, recursively call this function # giving that path and reducing the depth. if os.path.isdir(fullpath): renameFiles(fullpath, depth - 1) |
We are now ready to process a file that we find in a folder. We want to first build a new name for the file then test for a few things before renaming the file.
- That we are only changing image files
- We are not overwriting an existing file
- That we are in the correct folder
Once we are sure that these tests pass, we can rename the file and complete the function. Your function is then complete:
import os ''' Function: renameFiles Parameters: @path: The path to the folder you want to traverse @depth: How deep you want to traverse the folder. Defaults to 99 levels. ''' def renameFiles(path, depth=99): # Once we hit depth, return if depth < 0: return # Make sure that a path was supplied and it is not a symbolic link if os.path.isdir(path) and not os.path.islink(path): # We will use a counter to append to the end of the file name ind = 1 # Loop through each file in the start directory and create a fullpath for file in os.listdir(path): fullpath = path + os.path.sep + file # Again we don't want to follow symbolic links if not os.path.islink(fullpath): # If it is a directory, recursively call this function # giving that path and reducing the depth. if os.path.isdir(fullpath): renameFiles(fullpath, depth - 1) else: # Find the extension (if available) and rebuild file name # using the directory, new base filename, index and the old extension. extension = os.path.splitext(fullpath)[1] # We are only interested in changing names of images. # So if there is a non-image file in there, we want to ignore it if extension in ('.jpg','.jpeg','.png','.gif'): # We want to make sure that we change the directory we are in # If you do not do this, you will not get to the subdirectory names os.chdir(path) # Lets get the full path of the files in question dir_path = os.path.basename(os.path.dirname(os.path.realpath(file))) # We then define the name of the new path in order # The full path, then a dash, then 2 digits, then the extension newpath = os.path.dirname(fullpath) + os.path.sep + dir_path \ + ' - '+"{0:0=2d}".format(ind) + extension # If a file exists in the new path we defined, we probably do not want # to over write it. So we will redefine the new path until we get a unique name while os.path.exists(newpath): ind +=1 newpath = os.path.dirname(fullpath) + os.path.sep + dir_path \ + ' - '+"{0:0=2d}".format(ind) + extension # We rename the file and increment the sequence by one. os.rename(fullpath, newpath) ind += 1 return |
The last part is to add a line outside the function that executes it in the directory where the python file lives:
renameFiles(os.getcwd()) |
With this your code is complete. You can copy the code at the bottom of this post.
How do you use this?
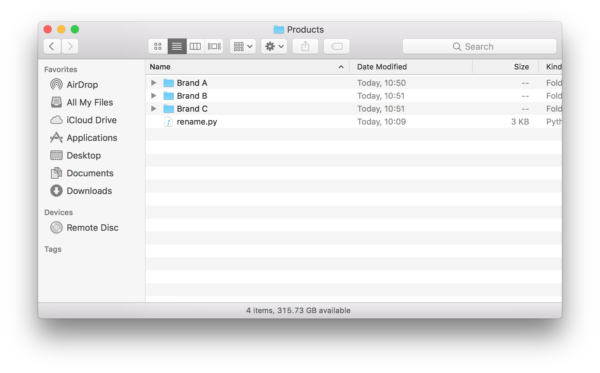
Once you have the file saved. Drop it in the folder of interest. In the image below, we have the file rename.py in the top most folder.
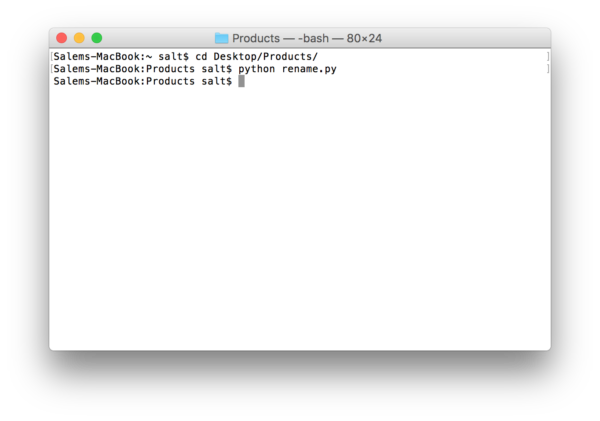
Next, you fire up terminal and type in “cd” followed by the folder where you saved your python script. Then type in “python” followed by the name of the python file you saved. In our case it is rename.py:
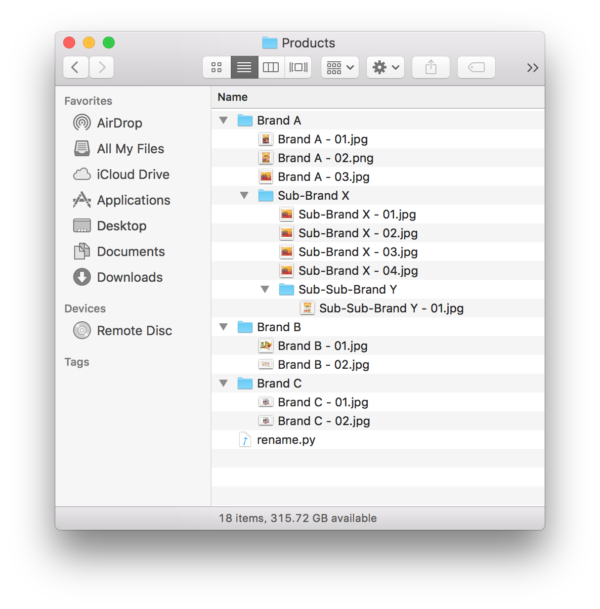
The results look like this:
The entire code
import os ''' Function: renameFiles Parameters: @path: The path to the folder you want to traverse @depth: How deep you want to traverse the folder. Defaults to 99 levels. ''' def renameFiles(path, depth=99): # Once we hit depth, return if depth < 0: return # Make sure that a path was supplied and it is not a symbolic link if os.path.isdir(path) and not os.path.islink(path): # We will use a counter to append to the end of the file name ind = 1 # Loop through each file in the start directory and create a fullpath for file in os.listdir(path): fullpath = path + os.path.sep + file # Again we don't want to follow symbolic links if not os.path.islink(fullpath): # If it is a directory, recursively call this function # giving that path and reducing the depth. if os.path.isdir(fullpath): renameFiles(fullpath, depth - 1) else: # Find the extension (if available) and rebuild file name # using the directory, new base filename, index and the old extension. extension = os.path.splitext(fullpath)[1] # We are only interested in changing names of images. # So if there is a non-image file in there, we want to ignore it if extension in ('.jpg','.jpeg','.png','.gif'): # We want to make sure that we change the directory we are in # If you do not do this, you will not get to the subdirectory names os.chdir(path) # Lets get the full path of the files in question dir_path = os.path.basename(os.path.dirname(os.path.realpath(file))) # We then define the name of the new path in order # The full path, then a dash, then 2 digits, then the extension newpath = os.path.dirname(fullpath) + os.path.sep + dir_path \ + ' - '+"{0:0=2d}".format(ind) + extension # If a file exists in the new path we defined, we probably do not want # to over write it. So we will redefine the new path until we get a unique name while os.path.exists(newpath): ind +=1 newpath = os.path.dirname(fullpath) + os.path.sep + dir_path \ + ' - '+"{0:0=2d}".format(ind) + extension # We rename the file and increment the sequence by one. os.rename(fullpath, newpath) ind += 1 return renameFiles(os.getcwd()) |
![]() Posted by Salem
Posted by Salem
![]() Apr 28
Apr 28

Collaborative Filtering with Python
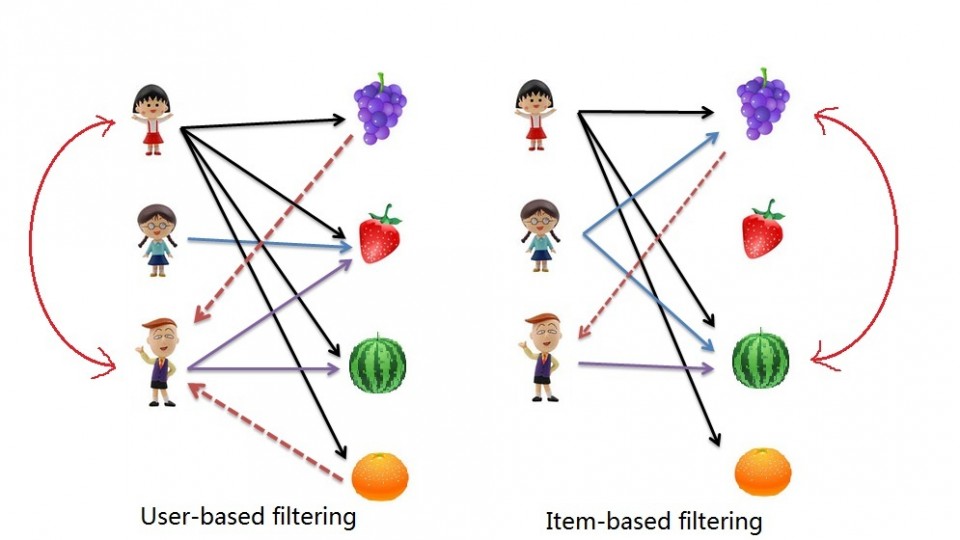
To start, I have to say that it is really heartwarming to get feedback from readers, so thank you for engagement. This post is a response to a request made collaborative filtering with R.
The approach used in the post required the use of loops on several occassions.
Loops in R are infamous for being slow. In fact, it is probably best to avoid them all together.
One way to avoid loops in R, is not to use R (mind: #blow). We can use Python, that is flexible and performs better for this particular scenario than R.
For the record, I am still learning Python. This is the first script I write in Python.
Refresher: The Last.FM dataset
The data set contains information about users, gender, age, and which artists they have listened to on Last.FM.
In our case we only use Germany’s data and transform the data into a frequency matrix.
We will use this to complete 2 types of collaborative filtering:
- Item Based: which takes similarities between items’ consumption histories
- User Based: that considers similarities between user consumption histories and item similarities
We begin by downloading our dataset:
Fire up your terminal and launch your favourite IDE. I use IPython and Notepad++.
Lets load the libraries we will use for this exercise (pandas and scipy)
# --- Import Libraries --- # import pandas as pd from scipy.spatial.distance import cosine |
We then want to read our data file.
# --- Read Data --- # data = pd.read_csv('data.csv') |
If you want to check out the data set you can do so using data.head():
data.head(6).ix[:,2:8] abba ac/dc adam green aerosmith afi air 0 0 0 0 0 0 0 1 0 0 1 0 0 0 2 0 0 0 0 0 0 3 0 0 0 0 0 0 4 0 0 0 0 0 0 5 0 0 0 0 0 0 |
Item Based Collaborative Filtering
Reminder: In item based collaborative filtering we do not care about the user column.
So we drop the user column (don’t worry, we’ll get them back later)
# --- Start Item Based Recommendations --- # # Drop any column named "user" data_germany = data.drop('user', 1) |
Before we calculate our similarities we need a place to store them. We create a variable called data_ibs which is a Pandas Data Frame (… think of this as an excel table … but it’s vegan with super powers …)
# Create a placeholder dataframe listing item vs. item data_ibs = pd.DataFrame(index=data_germany.columns,columns=data_germany.columns) |
Now we can start to look at filling in similarities. We will use Cosin Similarities.
We needed to create a function in R to achieve this the way we wanted to. In Python, the Scipy library has a function that allows us to do this without customization.
In essense the cosine similarity takes the sum product of the first and second column, then dives that by the product of the square root of the sum of squares of each column.
This is a fancy way of saying “loop through each column, and apply a function to it and the next column”.
# Lets fill in those empty spaces with cosine similarities # Loop through the columns for i in range(0,len(data_ibs.columns)) : # Loop through the columns for each column for j in range(0,len(data_ibs.columns)) : # Fill in placeholder with cosine similarities data_ibs.ix[i,j] = 1-cosine(data_germany.ix[:,i],data_germany.ix[:,j]) |
With our similarity matrix filled out we can look for each items “neighbour” by looping through ‘data_ibs’, sorting each column in descending order, and grabbing the name of each of the top 10 songs.
# Create a placeholder items for closes neighbours to an item data_neighbours = pd.DataFrame(index=data_ibs.columns,columns=range(1,11)) # Loop through our similarity dataframe and fill in neighbouring item names for i in range(0,len(data_ibs.columns)): data_neighbours.ix[i,:10] = data_ibs.ix[0:,i].order(ascending=False)[:10].index # --- End Item Based Recommendations --- # |
Done!
data_neighbours.head(6).ix[:6,2:4] 2 3 4 a perfect circle tool dredg deftones abba madonna robbie williams elvis presley ac/dc red hot chili peppers metallica iron maiden adam green the libertines the strokes babyshambles aerosmith u2 led zeppelin metallica afi funeral for a friend rise against fall out boy |
User Based collaborative Filtering
The process for creating a User Based recommendation system is as follows:
- Have an Item Based similarity matrix at your disposal (we do…wohoo!)
- Check which items the user has consumed
- For each item the user has consumed, get the top X neighbours
- Get the consumption record of the user for each neighbour.
- Calculate a similarity score using some formula
- Recommend the items with the highest score
Lets begin.
We first need a formula. We use the sum of the product 2 vectors (lists, if you will) containing purchase history and item similarity figures. We then divide that figure by the sum of the similarities in the respective vector.
The function looks like this:
# --- Start User Based Recommendations --- # # Helper function to get similarity scores def getScore(history, similarities): return sum(history*similarities)/sum(similarities) |
The rest is a matter of applying this function to the data frames in the right way.
We start by creating a variable to hold our similarity data.
This is basically the same as our original data but with nothing filled in except the headers.
# Create a place holder matrix for similarities, and fill in the user name column data_sims = pd.DataFrame(index=data.index,columns=data.columns) data_sims.ix[:,:1] = data.ix[:,:1] |
We now loop through the rows and columns filling in empty spaces with similarity scores.
Note that we score items that the user has already consumed as 0, because there is no point recommending it again.
#Loop through all rows, skip the user column, and fill with similarity scores for i in range(0,len(data_sims.index)): for j in range(1,len(data_sims.columns)): user = data_sims.index[i] product = data_sims.columns[j] if data.ix[i][j] == 1: data_sims.ix[i][j] = 0 else: product_top_names = data_neighbours.ix[product][1:10] product_top_sims = data_ibs.ix[product].order(ascending=False)[1:10] user_purchases = data_germany.ix[user,product_top_names] data_sims.ix[i][j] = getScore(user_purchases,product_top_sims) |
We can now produc a matrix of User Based recommendations as follows:
# Get the top songs data_recommend = pd.DataFrame(index=data_sims.index, columns=['user','1','2','3','4','5','6']) data_recommend.ix[0:,0] = data_sims.ix[:,0] |
Instead of having the matrix filled with similarity scores, however, it would be nice to see the song names.
This can be done with the following loop:
# Instead of top song scores, we want to see names for i in range(0,len(data_sims.index)): data_recommend.ix[i,1:] = data_sims.ix[i,:].order(ascending=False).ix[1:7,].index.transpose() |
# Print a sample print data_recommend.ix[:10,:4] |
Done! Happy recommending ;]
user 1 2 3 0 1 flogging molly coldplay aerosmith 1 33 red hot chili peppers kings of leon peter fox 2 42 oomph! lacuna coil rammstein 3 51 the subways the kooks franz ferdinand 4 62 jack johnson incubus mando diao 5 75 hoobastank papa roach sum 41 6 130 alanis morissette the smashing pumpkins pearl jam 7 141 machine head sonic syndicate caliban 8 144 editors nada surf the strokes 9 150 placebo the subways eric clapton 10 205 in extremo nelly furtado finntroll |
Entire Code
# --- Import Libraries --- # import pandas as pd from scipy.spatial.distance import cosine # --- Read Data --- # data = pd.read_csv('data.csv') # --- Start Item Based Recommendations --- # # Drop any column named "user" data_germany = data.drop('user', 1) # Create a placeholder dataframe listing item vs. item data_ibs = pd.DataFrame(index=data_germany.columns,columns=data_germany.columns) # Lets fill in those empty spaces with cosine similarities # Loop through the columns for i in range(0,len(data_ibs.columns)) : # Loop through the columns for each column for j in range(0,len(data_ibs.columns)) : # Fill in placeholder with cosine similarities data_ibs.ix[i,j] = 1-cosine(data_germany.ix[:,i],data_germany.ix[:,j]) # Create a placeholder items for closes neighbours to an item data_neighbours = pd.DataFrame(index=data_ibs.columns,columns=[range(1,11)]) # Loop through our similarity dataframe and fill in neighbouring item names for i in range(0,len(data_ibs.columns)): data_neighbours.ix[i,:10] = data_ibs.ix[0:,i].order(ascending=False)[:10].index # --- End Item Based Recommendations --- # # --- Start User Based Recommendations --- # # Helper function to get similarity scores def getScore(history, similarities): return sum(history*similarities)/sum(similarities) # Create a place holder matrix for similarities, and fill in the user name column data_sims = pd.DataFrame(index=data.index,columns=data.columns) data_sims.ix[:,:1] = data.ix[:,:1] #Loop through all rows, skip the user column, and fill with similarity scores for i in range(0,len(data_sims.index)): for j in range(1,len(data_sims.columns)): user = data_sims.index[i] product = data_sims.columns[j] if data.ix[i][j] == 1: data_sims.ix[i][j] = 0 else: product_top_names = data_neighbours.ix[product][1:10] product_top_sims = data_ibs.ix[product].order(ascending=False)[1:10] user_purchases = data_germany.ix[user,product_top_names] data_sims.ix[i][j] = getScore(user_purchases,product_top_sims) # Get the top songs data_recommend = pd.DataFrame(index=data_sims.index, columns=['user','1','2','3','4','5','6']) data_recommend.ix[0:,0] = data_sims.ix[:,0] # Instead of top song scores, we want to see names for i in range(0,len(data_sims.index)): data_recommend.ix[i,1:] = data_sims.ix[i,:].order(ascending=False).ix[1:7,].index.transpose() # Print a sample print data_recommend.ix[:10,:4] |
Referenence
- This case is based on Professor Miguel Canela’s “Designing a music recommendation app”
![]() Posted by Salem
Posted by Salem


Chatter