Customer Segmentation: Excel and R
![]() Posted by Salem on April 30, 2014
Posted by Salem on April 30, 2014

Foreward

I started reading Data Smart by John Foreman. The book is a great read because of Foreman’s humorous style of writing. What sets this book apart from the other data analysis books I have come across is that it focuses on the techniques rather than the tools – everything is accomplished through the use of a spreadsheet program (e.g. Excel).
So as a personal project to learn more about data analysis and its applications, I will be reproducing exercises in the book both in Excel and R. I will be structured in the blog posts: 0) I will always repeat this paragraph in every post 1) Introducing the Concept and Data Set, 2) Doing the Analysis with Excel, 3) Reproducing the results with R.
If you like the stuff here, please consider buying the book.
Shortcuts
This post is long, so here is a shortcut menu:
Excel
- Step 1: Pivot & Copy
- Step 2: Distances and Clusters
- Step 3: Solving for optimal cluster centers
- Step 4: Top deals by clusters
R
- Step 1: Pivot & Copy
- Step 2: Distances and Clusters
- Step 3: Solving for optimal cluster centers
- Step 4: Top deals by clusters
- Entire Code
Customer Segmentation
Customer segmentation is as simple as it sounds: grouping customers by their characteristics – and why would you want to do that? To better serve their needs!
So how does one go about segmenting customers? One method we will look at is an unsupervised method of machine learning called k-Means clustering. Unsupervised learning means finding out stuff without knowing anything about the data to start … so you want to discover.
Our example today is to do with e-mail marketing. We use the dataset from Chapter 2 on Wiley’s website – download a vanilla copy here
What we have are offers sent via email, and transactions based on those offers. What we want to do with K-Means clustering is classify customers based on offers they consume. Simplystatistics.org have a nice animation of what this might look like:
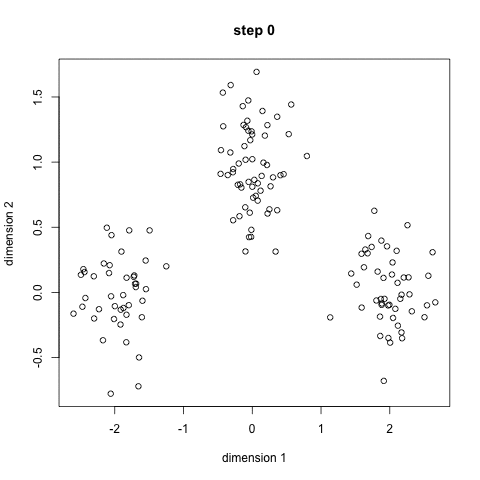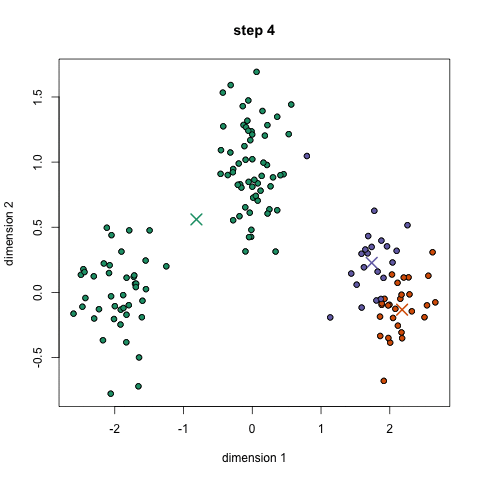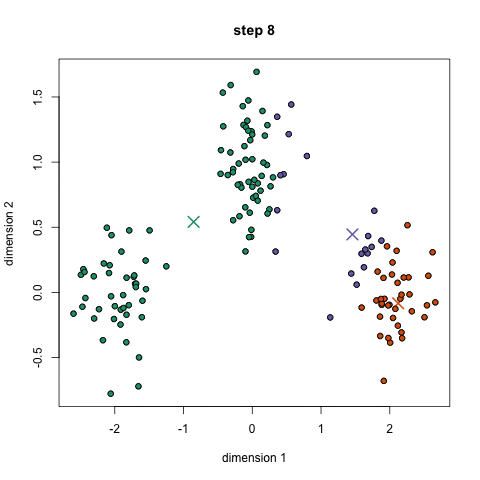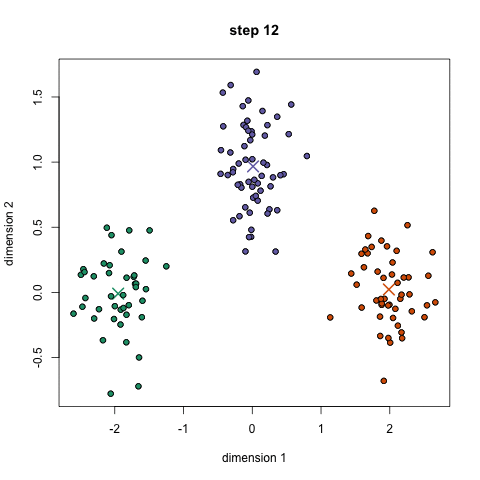
If we plot a given set of data by their dimensions, we can identify groups of similar points (customers) within the dataset by looking at how those points center around two or more points. The k in k-means is just the number of clusters you choose to identify; naturally this would be greater than one cluster.
Great, we’re ready to start.
K-Means Clustering – Excel
First what we need to do is create a transaction matrix. That means, we need to put the offers we mailed out next to the transaction history of each customer. This is easily achieved with a pivot table.
Step 1: Pivot & Copy
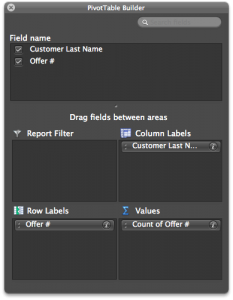 Go to your “transactions” tab and create a pivot table with the settings shown in the image to the right.
Go to your “transactions” tab and create a pivot table with the settings shown in the image to the right.
Once you have that you will have the names of the customers in columns, and the offer numbers in rows with a bunch of 1’s indicating that the customers have made a transaction based on the given offer.
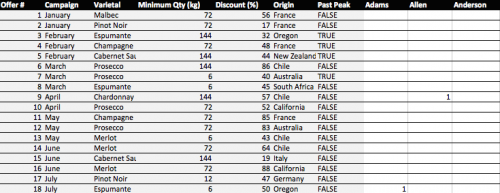
Great. Copy and paste the pivot table (leaving out the grand totals column and row) into a new tab called “Matrix”.
Now copy the table from the “OfferInformation” tab and paste it to the left of your new Matrix table.
Done – You have your transaction matrix! This is what it should look like:
If you would like to skip this step, download this file with Step 1 completed.
Step 2: Distances and Clusters
We will use k = 4 indicating that we will use 4 clusters. This is somewhat arbitrary, but the number you pick should be representative of the number of segments you can handle as a business. So 100 segments does not make sense for an e-mail marketing campaign.
Lets go ahead and add 4 columns – each representing a cluster.
We need to calculate how far away each customer is from the cluster’s mean. To do this we could use many distances, one of which is the Euclidean Distance. This is basically the distance between two points using pythagorean theorem.
To do this in Excel we will use a feature called multi-cell arrays that will make our lives a lot easier. For “Adam” insert the following formula to calculate the distance from Cluster 1 and then press CTRL+SHIFT+ENTER (if you just press enter, Excel wont know what to do):
=SQRT(SUM((L$2:L$33-$H$2:$H$33)^2)) |
Excel will automatically add braces “{}” around your formula indicating that it will run the formula for each row.
Now do the same for clusters 2, 3 and 4.
=SQRT(SUM((L$2:L$33-$I$2:$I$33)^2)) =SQRT(SUM((L$2:L$33-$J$2:$J$33)^2)) =SQRT(SUM((L$2:L$33-$K$2:$K$33)^2)) |
Now copy Adam’s 4 cells, highlight all the “distance from cluster …” cells for the rest of the customers, and paste the formula. You now have the distances for all customers.
Before moving on we need to calculate the cluster with the minimum distance. To do this we will add 2 rows: the first is “Minimum Distance” which for Adam is:
=MIN(L34:L37) |
Do the same for the remaining customers. Then add another row labelled “Assigned Cluster” with the formula:
=MATCH(L38,L34:L37,0) |
That’s all you need. Now lets go find the optimal cluster centers!
If you would like to skip this step, download this file with Step 2 completed.
Step 3: Solving for optimal cluster centers
We will use “Solver” to help us calculate the optimal centers. This step is pretty easy now that you have most of your model set up. The optimal centers will allow us to have the minimum distance for each customer – and therefore we are minimizing the total distance.
To do this, we first must know what the total distance is. So add a row under the “Assigned Cluster” and calculate the sum of the “Minimum Distance” row using the formula:
=SUM(L38:DG38) |
We are now ready to use solver (found in Tools -> Solver). Set up your solver to match the following screenshot.
Note that we change the solver to “evolutionary” and set options of convergence to 0.00001, and timeout to 600 seconds.

When ready, press solve. Go make yourself a coffee, this will take about 10 minutes.
Note: Foreman is able to achieve 140, I only reached 144 before my computer times out. This is largely due to my laptop’s processing power I believe. Nevertheless, the solution is largely acceptable.
I think it’s a good time to appropriately name your tab “Clusters”.
If you would like to skip this step, download this file with Step 3 completed.
Step 4: Top deals by clusters
Now we have our clusters – and essentially our segments – we want to find the top deals for each segment. That means we want to calculate, for each offer, how many were consumed by each segment.
This is easily achieved through the SUMIF function in excel. First lets set up a new tab called “Top Deals”. Copy and paste the “Offer Information” tab into your new Top Deals tab and add 4 empty columns labelled 1,2,3, and 4.
The SUMIF formula uses 3 arguments: the data you want to consider, the criteria whilst considering that data, and finally if the criteria is met what should the formula sum up. In our case we will consider the clusters as the data, the cluster number as the criteria, and the number of transactions for every offer as the final argument.
This is done using the following formula in the cell H2 (Offer 1, Cluster 1):
=SUMIF(Clusters!$L$39:$DG$39,'Top Deals'!H$1,Clusters!$L2:$DG2) |
Drag this across (or copy and paste into) cells H2 to K33. You now have your top deals! It’s not very clear though so add some conditional formatting by highlighting H2:K33 and selecting format -> conditional formatting. I added the following rule:
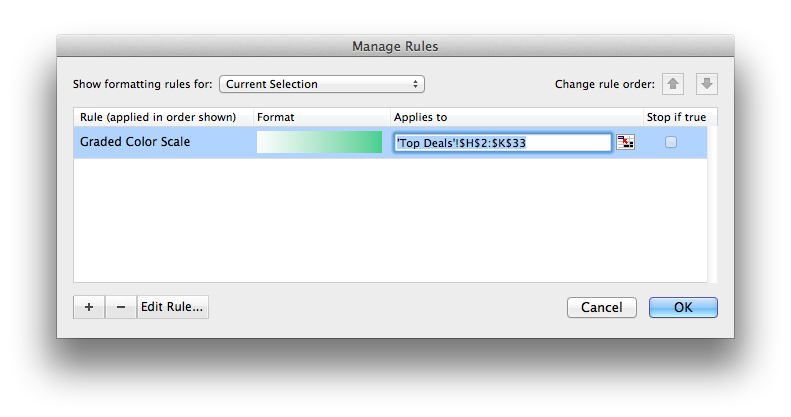
That’s it! Foreman goes into details about how to judge whether 4 clusters are enough but this is beyond the scope of the post. We have 4 clusters and our offers assigned to each cluster. The rest is interpretation. One observation that stands out is that cluster 4 was the only cluster that consumed Offer 22.
Another is that cluster 1 have clear preferences for Pinot Noir offers and so we will push Pinot Noir offers to: Anderson, Bell, Campbell, Cook, Cox, Flores, Jenkins, Johnson, Moore, Morris, Phillips, Smith. You could even use a cosine similarity or apriori recommendations to go a step further with Cluster 1.
We are done with Excel, now lets see how to do this with R!
If you would like to skip this step, download this file with Step 4 completed.
K-Means Clustering – R
We will go through the same steps we did. We start with our vanilla files – provided in CSV format:
Download these files into a folder where you will work from in R. Fire up RStudio and lets get started.
Step 1: Pivot & Copy
First we want to read our data. This is simple enough:
# Read offers and transaction data offers<-read.csv(file="OfferInformation.csv") transactions<-read.csv(file="Transactions.csv") |
We now need to combine these 2 files to get a frequency matrix – equivalent to pivoting in Excel. This can be done using the reshape library in R. Specifically we will use the melt and cast functions.
We first melt the 2 columns of the transaction data. This will create data that we can pivot: customer, variable, and value. We only have 1 variable here – Offer.
We then want to cast this data by putting value first (the offer number) in rows, customer names in the columns. This is done by using R’s style of formula input: Value ~ Customers.
We then want to count each occurrence of customers in the row. This can be done by using a function that takes customer names as input, counts how many there are, and returns the result. Simply: function(x) length(x)
Lastly, we want to combine the data from offers with our new transaction matrix. This is done using cbind (column bind) which glues stuff together automagically.
Lots of explanations for 3 lines of code!
#Load Library library(reshape) # Melt transactions, cast offer by customers pivot<-melt(transactions[1:2]) pivot<-(cast(pivot,value~Customer.Last.Name,fill=0,fun.aggregate=function(x) length(x))) # Bind to offers, we remove the first column of our new pivot because it's redundant. pivot<-cbind(offers,pivot[-1]) |
We can output the pivot table into a new CSV file called pivot.
write.csv(file="pivot.csv",pivot)
Step 2: Clustering
To cluster the data we will use only the columns starting from “Adams” until “Young”.
We will use the fpc library to run the KMeans algorithm with 4 clusters.
To use the algorithm we will need to rotate the transaction matrix with t().
That’s all you need: 4 lines of code!
# Load library library(fpc) # Only use customer transaction data and we will rotate the matrix cluster.data<-pivot[,8:length(pivot)] cluster.data<-t(cluster.data) # We will run KMeans using pamk (more robust) with 4 clusters. cluster.kmeans<-pamk(cluster.data,k=4) # Use this to view the clusters View(cluster.kmeans$pamobject$clustering) |
Step 3: Solving for Cluster Centers
This is not a necessary step in R! Pat yourself on the back, get another cup of tea or coffee and move onto to step 4.
Step 4: Top deals by clusters
Top get the top deals we will have to do a little bit of data manipulation. First we need to combine our clusters and transactions. Noteably the lengths of the ‘tables’ holding transactions and clusters are different. So we need a way to merge the data … so we use the merge() function and give our columns sensible names:
#Merge Data cluster.deals<-merge(transactions[1:2],cluster.kmeans$pamobject$clustering,by.x = "Customer.Last.Name", by.y = "row.names") colnames(cluster.deals)<-c("Name","Offer","Cluster") |
We then want to repeat the pivoting process to get Offers in rows and clusters in columns counting the total number of transactions for each cluster. Once we have our pivot table we will merge it with the offers data table like we did before:
# Melt, cast, and bind cluster.pivot<-melt(cluster.deals,id=c("Offer","Cluster")) cluster.pivot<-cast(cluster.pivot,Offer~Cluster,fun.aggregate=length) cluster.topDeals<-cbind(offers,cluster.pivot[-1]) |
We can then reproduce the excel version by writing to a csv file:
write.csv(file="topdeals.csv",cluster.topDeals,row.names=F) |
Note
It’s important to note that cluster 1 in excel does not correspond to cluster 1 in R. It’s just the way the algorithms run. Moreover, the allocation of clusters might differ slightly because of the nature of kmeans algorithm. However, your insights will be the same; in R we also see that cluster 3 prefers Pinot Noir and cluster 4 has a strong preference for Offer 22.
Entire Code
# Read data offers<-read.csv(file="OfferInformation.csv") transactions<-read.csv(file="Transactions.csv") # Create transaction matrix library(reshape) pivot<-melt(transactions[1:2]) pivot<-(cast(pivot,value~Customer.Last.Name,fill=0,fun.aggregate=function(x) length(x))) pivot<-cbind(offers,pivot[-1]) write.csv(file="pivot.csv",pivot) # Cluster library(fpc) cluster.data<-pivot[,8:length(pivot)] cluster.data<-t(cluster.data) cluster.kmeans<-pamk(cluster.data,k=4) # Merge Data cluster.deals<-merge(transactions[1:2],cluster.kmeans$pamobject$clustering,by.x = "Customer.Last.Name", by.y = "row.names") colnames(cluster.deals)<-c("Name","Offer","Cluster") # Get top deals by cluster cluster.pivot<-melt(cluster.deals,id=c("Offer","Cluster")) cluster.pivot<-cast(cluster.pivot,Offer~Cluster,fun.aggregate=length) cluster.topDeals<-cbind(offers,cluster.pivot[-1]) write.csv(file="topdeals.csv",cluster.topDeals,row.names=F) |

![]() Category: Code
Category: Code
![]() Tags: clustering, excel, kmeans, R, segmentation
Tags: clustering, excel, kmeans, R, segmentation


Hello,
While I was going through this tutorial, I just thought of sharing an experience of mine. I recently came across this site,www.jolicharts.com for data visualization and creating charts derived directly from excel sheets.
It was good for me as day to day charting and data presentation was taking way too much of my time..
I hope this info also might help few more of us.
Well no harm in trying it for free..
Excellent post!!
Great Post – Thanks!
Your blog post is simply amazing! You have a gift of explaining data analysis topics with great insights. Thank you.
Manju
Hi! Nice post, works good!
I was wondering if you have a nice way to visualize the produced clusters?
Cheers,
Johan
I;m new to clustering and segmentation. I have a question around this, my solver query is not working. There is a run time error.
Are there supposed to be values in the cluster columns before you run solver?